I found it difficult to sleep last night. The reason is that I attended a symposium yesterday, and was exposed to so many new ideas that I’m having to do quite a bit of processing. Actually, that’s quite exciting. I often enjoy conferences, but rarely come away buzzing from them. Now, I normally wouldn’t write about a conference so soon after attending it, but I wanted to bring a few things to your attention straight away. I’m sure you’ll find them interesting in their own right (at least, I hope you do), and you may wish to discuss them with your students. It’s all part of my quest to show that computing and ICT can be interesting and enjoyable, and not just for geeks.
The conference in question was the British Library Labs Symposium. BL Labs exists to encourage researchers to explore its digital collections to answer research questions. When you consider that the British Library houses 150 million items, around 9 million of which have been digitised, you’ll realise that there’s a huge amount of data to explore. In fact, that figure of 9 million is an under-estimate, because some of those “items” – books, journals, and so on – are collections in themselves.
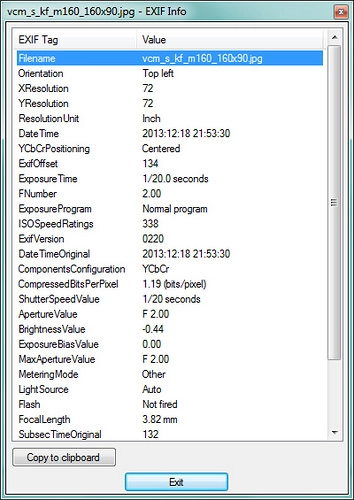
I’m not going to describe the entire conference in detail, or even comprehensively, but pick out the items I found of particular interest. But first, a word about that word “data”. What’s especially important for research is the use of meta-data. For example, the EXIF data for a photo, such as that shown in the following screenshot, is meta-data. If it was encoded in a particular format, with perhaps the tags data (ie the words people have used to tag the photo), then you would be able to search through a large amount of data and extract the bits that are relevant to your enquiry.
The hidden meta-data in a photograph
To take a different sort of example, the following slide is taken from the presentation by Bob Nicholson (see below), and shows how a joke has been meta-tagged. The and tags indicate that the enclosed text is a joke (as opposed to a news item, say), while the “t” tags refer to the title of the joke as it originally appeared in a publication.
It's the way you tell them

Now, in theory, you could use data mining techniques to search educational research data and come to conclusions about what sort of approach is useful with what kind of students. For individual schools, you could find out which teachers were most effective with particular types of student, on particular days and in particular locations. I say “in theory” because educational research data is stored all over the place, and in different formats, which is why I think there is not yet conclusive academic evidence that using education technology has any beneficial effect on learning. I may be wrong, but I don’t think the “big data/analytics” age of enlightenment is going to be dawning any time soon, despite what its proselytisers would have us believe. Actually, I am not even convinced it is unequivocally a good thing, but that’s an issue for another article. In the meantime, there’s an interesting article over at The Economist that you may wish to look at: Withered InBloom.
I’ve always had misgivings about the whole idea of big data myself because it ignores the small stuff. So it was very refreshing indeed to listen to Tim Hitchcock talking about the importance of small data – the power of the particular, as he put it. He also made the very important point that big data does two things: it ignores the “outliers”, which may be of vital interest in themselves. Also, because there is so much of it, you can get away with using what he referred to as “dirty data”. I need to explore his ideas further, but I thought his talk was very thought-provoking and timely. Tim is professor of Digital History at the University of Sussex, and has been exploring the use of large data sets and modern computing techniques in examining the past. You may find this blog post of particular interest in this regard: Big Data for Dead People: Digital Readings and the Conundrums of Positivism.
Another talk I found very interesting was the Victorian Meme Machine, by Bob Nicholson. This is an attempt to discover jokes in Victorian publications, and then superimpose the jokes on Victorian illustrations. It’s a very interesting idea, and there is even going to be an automatically tweeted Victorian Joke every day. I’ve written more about the project and how it works here: Victorian Humour.
Well, that’s enough for now. I intend to write about another project and another one of the talks in a day or two.
cross-posted at www.ictineducation.org
Terry Freedman is an independent educational ICT consultant with over 35 years of experience in education. He publishes the ICT in Education website and the newsletter “Digital Education."
